3. 비선형 자료 구조
✨비선형 자료 구조
일렬로 나열하지 않고 자료 순서나 관계가 복잡한 구조를 말함
1. 그래프
정점과 간선으로 이루어진 자료 구조
정점과 간선
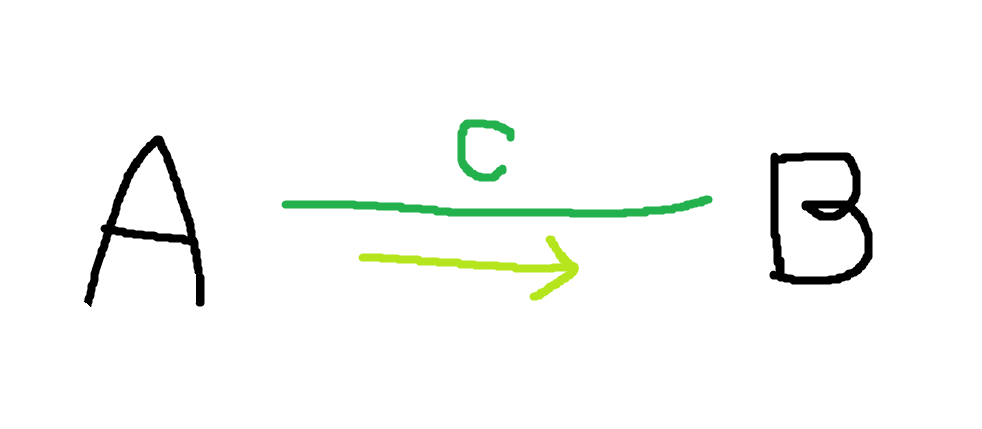
A에서 B로 C를 통해 간다고 했을 때 ‘B’는 정점(vertex)이 되고 ‘C’는 간선(edge)이다.
단방향 간선 : 한쪽으로만 이동 가능
양방향 간선 : 양쪽으로 이동 가능
정점으로 나가는 간선 : 해당 정점의 outdegree
들어오는 간선 : 해당 정점의 indegree
정점은 약자로 V 또는 U라고 하며, 보통 “U에서부터 V로 간다.”라고 표현
정점과 간선으로 이루어진 집합을 ‘그래프(graph)’라고 한다.
가중치
가중치는 간선과 정점 사이에 드는 비용
1번 노드와 2번 노드까지 가는 비용이 한 칸이라면 1번 노드에서 2번 노드까지의 가중치는 한 칸
2. 트리
그래프 중 하나로 그래프의 특징처럼 정점과 간선으로 이루어져 있고, 트리 구조로 배열된 일종의 계층적 데이터의 집합
트리로 이루어진 집합을 숲이라고 한다.

트리의 특징
1. 부모, 자식 계층 구조를 가진다.
같은 경로상에서 어떤 노드보다 위에 있으면 부모, 아래에 있으면 자식 노드가 된다.
2. V - 1 = E라는 특징이 있다. 간선 수는 노드 수 - 1이다.
3. 임의의 두 노드 사이의 경로는 ‘유일무이’하게 ‘존재’한다.
즉, 트리 내의 어떤 노드와 어떤 노드까지의 경로는 반드시 있다.
트리의 구성
루트노드
가장 위에 있는 노드
내부노드
루트 노드와 내부 노드 사이에 있는 노드
리프노드
자식 노드가 없는 노드
트리의 높이와 레벨

깊이
트리에서의 깊이는 각 노드마다 다르며, 루트 노드부터 특정 노드까지 최단 거리로 갔을 때의 거리
ex ) F 노드의 깊이 : 2
높이
트리의 높이는 루트 노드부터 리프 노드까지 거리 중 가장 긴 거리
ex ) 앞 그림의 트리 높이 : 4
레벨
트리의 레벨은 주어지는 문제마다 조금씩 다르지만 보통 깊이와 같은 의미
서브트리
트리 내의 하위 집합
트리 내에 있는 부분집합이라고도 볼 수 있음
지금 보면 B, F, G 노드가 이 트리의 하위 집합으로 “저 노드들은 서브트리이다.”라고 한다.
이진트리
자식의 노드 수가 두 개 이하인 트리를 의미

• 정이진 트리(full binary tree): 자식 노드가 0 또는 두 개인 이진 트리
• 완전 이진 트리(complete binary tree): 왼쪽에서부터 채워져 있는 이진 트리를 의미
마지막 레벨을 제외하고는 모든 레벨이 완전히 채워져 있으며, 마지막 레벨의 경우 왼쪽부터 채워져 있다.
• 변질 이진 트리(degenerate binary tree): 자식 노드가 하나밖에 없는 이진 트리
• 포화 이진 트리(perfect binary tree): 모든 노드가 꽉 차 있는 이진 트리
• 균형 이진 트리(balanced binary tree): 왼쪽과 오른쪽 노드의 높이 차이가 1 이하인 이진 트리
map, set을 구성하는 레드 블랙 트리는 균형 이진 트리 중 하나이다.
이진 탐색 트리 (BST)

노드의 오른쪽 하위 트리에는 ‘노드 값보다 큰 값’이 있는 노드만 포함되고, 왼쪽 하위 트리에는 ‘노드 값보다 작은 값’이 들어 있는 트리
- 검색에 용이
- 보통 탐색 시간 복잡도: O(logn)
- 최악의 경우 시간 복잡도 : O(n)
AVL트리 (Adelson-Velsky and Landis tree)

규칙 : 최악의 경우를 배제하고 항상 균형 잡힌 트리로 만들자
앞서 설명한 최악의 경우 선형적인 트리가 되는 것을 방지하고 스스로 균형을 잡는 이진 탐색 트리
두 자식 서브트리의 높이는 항상 최대 1만큼 차이 난다는 특징
- 최악의 경우 시간 복잡도 : O(n)
- 탐색, 삽입, 삭제 모두 시간 복잡도 : O(logn)
- 삽입, 삭제를 할 때마다 균형이 안 맞는 것을 맞추기 위해 트리 일부를 왼쪽 혹은 오른쪽으로 회전시키며 균형을 잡
레드 블랙 트리
규칙 : 모든 리프 노드와 루트 노드는 블랙이고 어떤 노드가 레드이면 그 노드의 자식은 반드시 블랙이다.
각 노드는 빨간색 또는 검은색의 색상을 나타내는 추가 비트를 저장
노드의 색은 삽입 및 삭제 중에 트리가 균형을 유지하도록 하는 데 사용

- 노드는 레드 혹은 블랙 중의 하나이다.
- 루트 노드는 블랙이다.
- 모든 리프 노드들(NIL)은 블랙이다.
- 레드 노드의 자식노드 양쪽은 언제나 모두 블랙이다. (즉, 레드 노드는 연달아 나타날 수 없으며, 블랙 노드만이 레드 노드의 부모 노드가 될 수 있다)
- 어떤 노드로부터 시작되어 그에 속한 하위 리프 노드에 도달하는 모든 경로에는 리프 노드를 제외하면 모두 같은 개수의 블랙 노드가 있다.
3. 힙
완전 이진 트리 기반의 자료 구조
최소힙과 최대힙 두 가지가 있고 해당 힙에 따라 특정한 특징을 지킨 트리
최대힙
루트 노드에 있는 키는 모든 자식에 있는 키 중에서 가장 커야 함
또한, 각 노드의 자식 노드와의 관계도 이와 같은 특징이 재귀적으로 이루어져야 합니다.
최소힙
최소힙에서 루트 노드에 있는 키는 모든 자식에 있는 키 중에서 최솟값이어야 합니다.
또한, 각 노드의 자식 노드와의 관계도 이와 같은 특징이 재귀적으로 이루어져야 합니다.
최대 힙의 삽입

힙에 새로운 요소가 들어오면, 일단 새로운 노드를 힙의 마지막 노드에 이어서 삽입
이 새로운 노드를 부모 노드들과의 크기를 비교하며 교환해서 힙의 성질을 만족
최대 힙의 삭제
최대힙에서 최댓값은 루트 노드이므로 루트 노드가 삭제되고
이후 마지막 노드와 루트 노드를 스왑하여 또다시 스왑 등의 과정을 거쳐 재구성
4. 우선순위 큐
우선순위 대기열이라고도 하며, 대기열에서 우선순위가 높은 요소가 우선순위가 낮은 요소보다 먼저 제공되는 자료 구조
우선순위 큐는 힙을 기반으로 구현됩니다.

다음 코드처럼 greater를 써서 오름차순, less를 써서 내림차순으로 바꿀 수 있습니다. int뿐만 아니라 다른 자료 구조를 넣어서 할 수도 있습니다.
#include <bits/stdc++.h>
using namespace std;
priority_queue<int, vector<int>, greater<int> > pq; // 오름차순
// priority_queue<int, vector<int>, less<int> > pq; // 내림차순
int main() {
pq.push(5);
pq.push(4);
pq.push(3);
pq.push(2);
pq.push(1);
cout << pq.top() << "\n";
return 0;
}
/*
1
*/5. 맵 (map)
특정 순서에 따라 키와 매핑된 값의 조합으로 형성된 자료 구조
레드 블랙 트리 자료 구조를 기반으로 형성되고, 삽입하면 자동으로 정렬
c++언어 기준
맵을 쓸 때는 map<string, int> 형태로 구현
배열과 비슷하게 clear() 함수로 맵에 있는 모든 요소를 삭제할 수 있으며, size()로 map 크기를 구할 수 있다.
erase()로 해당 키와 키에 매핑된 값을 지울 수 있다.
해시 테이블을 구현할 때 쓰며 정렬을 보장하지 않는 unordered_map과 정렬을 보장하는 map 두 가지 종류
map을 순회할 때는 키에 해당하는 값(key)을 first, 키에 매핑된 값(value)에 해당하는 값을 second로 탐색 가능
6. 셋 ( set )
특정 순서(중위순회)에 따라 고유한 요소를 저장하는 컨테이너
중복되는 요소는 없고 오로지 희소한(unique) 값만 저장하는 자료 구조
파이썬 set
- set은 수학에서 이야기하는 집합과 비슷
- 순서가 없고, 집합안에서는 unique한 값을 가짐
- mutable 객체
- 중괄호를 사용하는 것은 dictionary와 비슷하지만, key가 없고 값만 존재
C++ set
- 연관 컨테이너(associative container) 중 하나
- 노드 기반 컨테이너 이며 균형 이진트리로 구현
- Key라 불리는 원소들의 집합으로 이루어진 컨테이너 (원소 = key)
- key값은 중복이 허용 X
- 원소가 insert 멤버 함수에 의해 삽입이 되면, 원소는 자동으로 정렬
- default 정렬기준은 less(오름차순)
7. 해시 테이블
해시 테이블은 무한에 가까운 데이터들을 유한한 개수의 해시 값으로 매핑한 테이블
삽입, 삭제, 탐색 시 평균적으로 O(1)의 시간 복잡도를 가짐
unordered_map으로 구현
특징
- (Key, Value)로 데이터를 저장하는 자료구조 중 하나로 빠르게 데이터를 검색할 수 있는 특징
- 해시 테이블이 빠른 검색속도를 제공하는 이유는 내부적으로 배열(버킷)을 사용하여 데이터를 저장하기 때문
- 해시 테이블은 각각의 Key값에 해시함수를 적용해 배열의 고유한 index를 생성하고, 이 index를 활용해 값을 저장하거나 검색함.
- 여기서 실제 값이 저장되는 장소를 버킷 또는 슬롯이라고 한다.